Jose V. Die
Ramon y Cajal Research Fellow
Department of Genetics-ETSIAM
University of Cordoba
Unix
get the radio show length (in seconds)
mdls *.mp3
mdls *.mp3 | grep kMDItemDurationSeconds
mdls *.mp3 | grep kMDItemDurationSeconds | cut -d '=' -f 2
mdls *.mp3 | grep kMDItemDurationSeconds | cut -d '=' -f 2 | cut -c 2-
mdls *.mp3 | grep kMDItemDurationSeconds | cut -d '=' -f 2 | cut -c 2- > duracion.csv
get the name of each episode
mdls *.mp3 | grep kMDItemDisplayName
mdls *.mp3 | grep kMDItemDisplayName | cut -d '=' -f 2
mdls *.mp3 | grep kMDItemDisplayName | cut -d '=' -f 2 | cut -c 2-
mdls *.mp3 | grep kMDItemDisplayName | cut -d '=' -f 2 | cut -c 2- > episodios.csv
R
Dependencies
library(stringr)
library(lubridate)
library(ggplot2)
library(dplyr)
Read the file with the radio show length (in seconds)
segundos <- readLines("duracion.csv")
Read the file with the radio show date
fechas <- readLines("episodios.csv")
Check both files have the same elements
length(segundos) == length(fecha)
Split each element based on a pattern
tmp <- str_split(fecha, "-cvradio")
tmp <- unlist(tmp)
Three episodes require manually edition.
The date for each episode can be found in the A Ciencia Cierta podcast website .
tmp[1] = "\"acienciacierta01122016"
tmp[3] = "\"acienciacierta22122016"
tmp[9] = "\"acienciacierta19012017"
Now, we select only those elements containing the date based on a pattern
str_subset(tmp, "acienciacierta")
The date is contained in the last eight elements
str_sub(str_subset(tmp, "acienciacierta"), -8, -1)
We can use the parser dmy from the lubridate package
fechas <- dmy(str_sub(str_subset(tmp, "acienciacierta"), -8, -1))
Simple plot on weekdays when the radio show is on
qplot(weekdays(fechas))
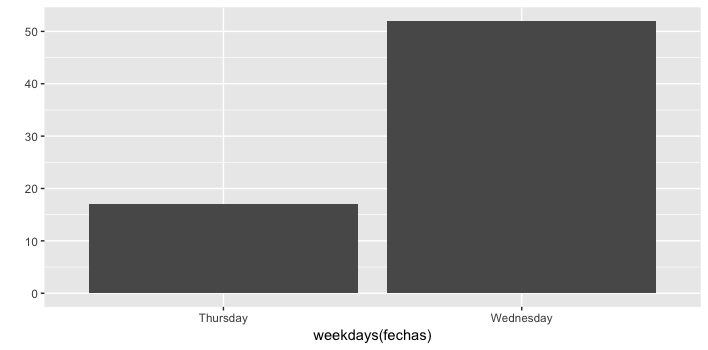
Finally, we make a new dataset, so we can use it in ggplot2
dat <- tibble(fecha = fechas,
minutos = as.numeric(segundos / 60)
dat %>% ggplot(aes(x = fecha, y = minutos)) +
geom_point() +
geom_smooth(method = "lm", col = "steelblue") +
ggtitle("A ciencia cierta", "Antonio Rivera")
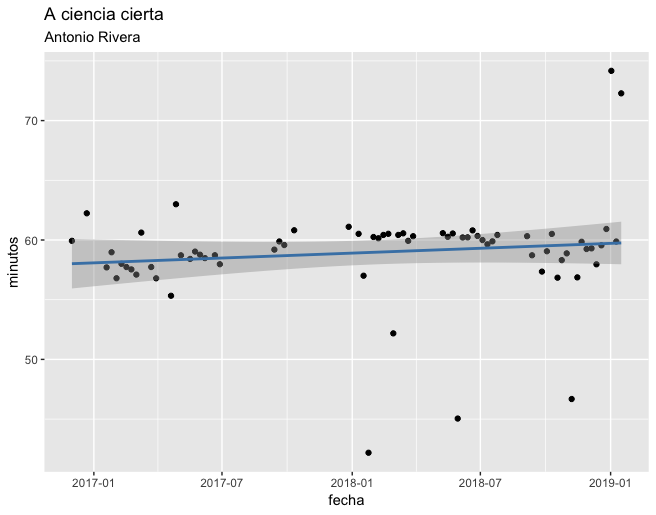
A regression linear model :
my_model = lm(data = dat, minutos~fecha)
summary(my_model)
# coefficients(my_model)